From Naive to Agentic RAG
Moving beyond basic retrieval-augmented generation to orchestration-driven AI systems using Google ADK.
Hi, my dear friends 👋
I’m continuing my journey into AI systems, and the natural next step after naive RAG turned out not to be “better embeddings” or “a bigger model,” but something more fundamental: agentic RAG.
Before touching any framework, I had to stop and answer two questions:
- What real scenario am I actually trying to solve, even if this is just an educational experiment?
- What kind of tooling would let me explore that scenario without locking me into a dead end?
From documents to decisions
Let’s start with a simple use case. Imagine a sales manager who wants to review planned vs. actual sales on a monthly basis.
The information already exists, but it’s scattered:
- Last year’s sales plan lives in a presentation, where someone confidently “promised” certain numbers.
- Actual sales data lives in a corporate database, accessible only via queries.
- The formats don’t match. Slides aren’t tables. Tables aren’t charts.
So what happens in practice?
- Search for the right presentation
- Write a database query
- Copy numbers from slides into Excel
- Paste query results into the same Excel file
- Build a chart That’s a lot of manual work for a question that sounds trivial in the age of AI.
Now imagine the same manager simply typing:
“Compare the sales plan with the actual sales for last year and generate a report.” No coffee-making assistant. A real AI agent. 🤖
At this point, the problem stops being about retrieving documents and starts looking like reasoning, coordination, and execution.
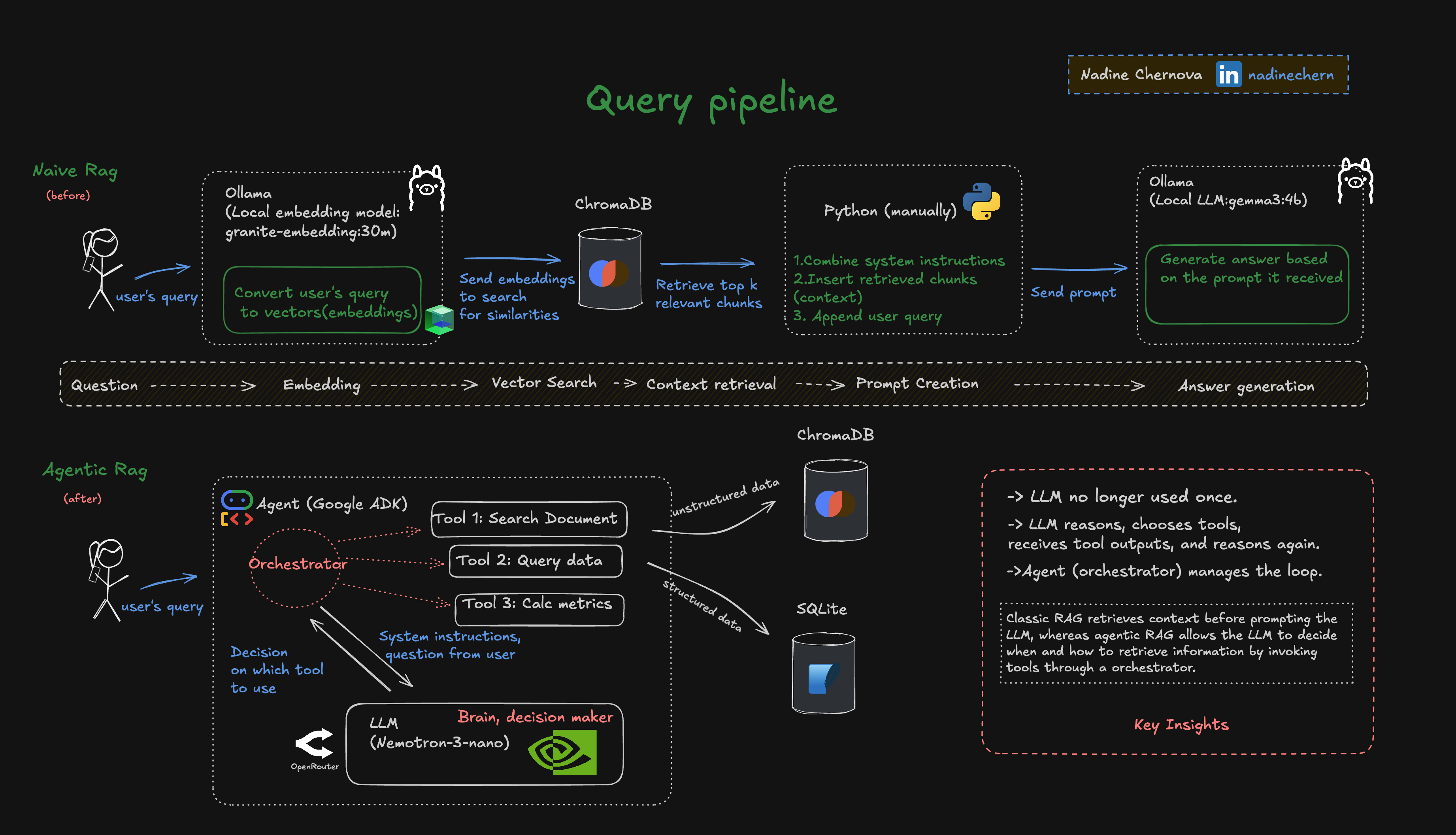
Why naive RAG isn’t enough
Naive RAG works well when:
- You already know which document matters
- You mainly need textual context injected into a prompt
But this scenario requires much more:
- Finding the right presentation
- Extracting structured data from slides
- Querying a database for actuals
- Normalizing two different data formats
- Comparing the results
- Deciding how to present the outcome
This is no longer retrieval. It’s orchestration.
Choosing the tool
This is where things got tricky.
There are already tools on the market that appear to solve this problem. But I wanted something that:
- Can switch models and providers easily
- Production-oriented
- Supports multi-agent patterns
After exploring a few options, I decided to experiment with Google ADK.
From a query to a system
So now we have:
- A single natural-language request: “Compare the sales plan with the actual sales for the last year and generate a report.”
- And a developer framework capable of planning, executing, and coordinating multiple steps instead of pretending everything happens in one prompt.
The interesting part isn’t the final report. It’s how the system gets there.
That’s where the transition from naive RAG to agentic RAG becomes visible and where the real learning begins.
I’ll break this down visually and show how responsibilities shift from simple retrieval to planning, tool use, and decision-making.
From simple retrieval to orchestration-driven AI
Check out the code: basic_agentic_rag on GitHub